The ease.ml Project
The fundemental hypothesis of ease.ml is that future machine learning platforms should manage the end-to-end process of building ML applications, beyond simplying making training a single model faster and automatic.
What is the right level of abstraction that future ML platforms should provide to its end users in order to unleash the full potential of machine learning to non-ML-experts such as biologists, astronomers, social scientists, or generally non-ML software engineers? We believe that understanding this question is the key to unleash the profound impact of ML to society in the near future. In ease.ml, we are inspired by our experience working with a diverse range of domain experts (See Applications) and our own explorations on distributed scalable learning (See ZipML) – Our belief is that the usability of a learning system should go beyond performance, scalability, and automation, instead, we should aim at managing the end-to-end process of building ML applications and provide systematic guidelines for an end-user. This view opens up a series of fundamental and challenging problems; and our personal view on many of them lead to the end-to-end ease.ml process.
The ease.ml Journey
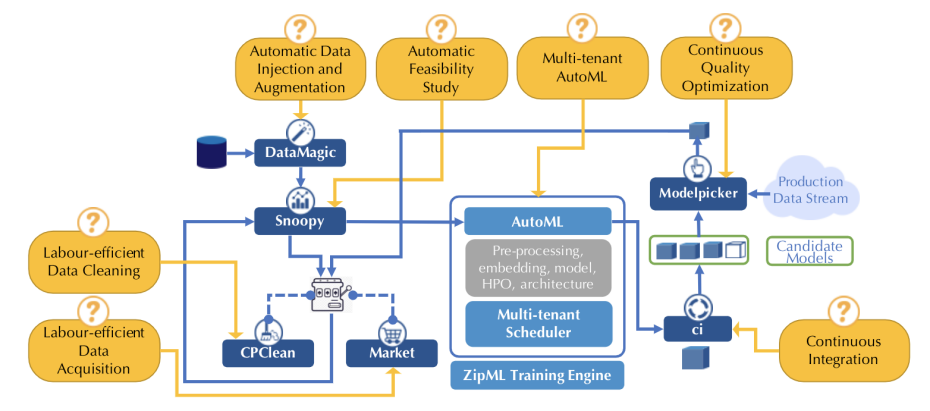
The ease.ml process consists of three stacks – apart from the standard AutoML stack, the Ease.ml process starts before an ML application is even modelled — by the Pre-ML Stack — and finishes at the Post-ML “MLOps” stack. Built as a thin layer over existing data ecosystems and techniques (such as amazing work done by other researchers including Snorkel, Label box, Holocleans, Kubeflow, etc.), ease.ml guides a non-expert user step-by-step: Starting by automatic data ingestion and augmentation (ease.ml/DataMagic), automatic feasibility study (ease.ml/snoopy), data noise debugging (CPClean), data acquisition (Market), scalable multi-tenant automatic training (ease.ml/AutoML), continuous integration (ease.ml/ci), and ending with label-efficient continuous quality optimization (ease.ml/ModelPicker). By following this process, we hope that an end user, without deep understanding of ML techniques, is able to construct ML applications without falling into many common pitfalls (e.g., overfitting, domain drifting, ill-defined tasks or overly noisy datasets).
System Summary
To enable ease.ml, we designed an, in our opinion, interesting schema of our data, model, and the process. For example, uncertainty is a first class citizen in our data model and we enforce a clear separation between four pillars of data: training set, development set, stable test set, and realtime test set. Another example is that we model the data flow in the MLOps cycles as an endless stream of models.
LA Melgar,
[CIDR] Conference on Innovative Data Systems Research
Abstract
We present Ease.ML, a lifecycle management system for machine learning (ML). Unlike many existing works, which focus on improving individual steps during the lifecycle of ML application development, Ease.ML focuses on managing and automating the entire lifecycle itself. We present user scenarios that have motivated the development of Ease.ML, the eight-step Ease.ML process that covers the lifecycle of ML application development; the foundation of Ease.ML in terms of a probabilistic database model and its connection to information theory; and our lessons learned, which hopefully can inspire future research.
System Components
Modern ML applications are often data hungry --- sometimes it is caused by the extensive process of data collection, and sometimes it is caused by the striking diversity of the data format that makes it hard to construct a homogeneous large dataset. Given an input dataset from the user, the first step of the ease.ml process, ease.ml/DataMagic, aims at providing functionalities of automatic data augmentation (adding new data examples automatically) and automatic data ingestion (automatically normalizing data into the same, machine readable, format).
Machine learning is no panacea — if your data are 20% wrong but you are hoping for 90% accuracy to make a profit out of your model, it is highly likely that it is doomed to fail. In our experience, we were surprised by how often an end user has a staggering mismatch between the quality of their data an the expectation of the accuracy that an ML model can achieve.
What if ease.ml/snoopy thinks your data is not good enough for ML to reach your quality target? In this case, it might be counterproductive to fire up an expensive ML training process, instead, we hope to help the user to understand their data better and make a more informative decision.
If data cleaning won’t increase your accuracy by too much, another potential reason of unsatisfactory ML quality is simply that you don’t have enough amount of data. If CPClean advices the user against data cleaning, she needs to acquire more data. Market is the next ease.ml component that helps the user with this.
If ease.ml/snoopy said “Yes” and we can finally fire up our ML training process! Given a dataset, ease.ml contains an AutoML component that outputs a ML model without any user intervention. There are three aspects of ease.ml/AutoML that makes it special.
Machine learning models are software artefacts. Among the stream of models generated by ease.ml/AutoML, not all of them satisfy the based requirement of real-world deployment. Can we continuously test ML models in the way we are testing traditional softwares?
All models that pass ease.ml/ci, in principle, can be deployed. This gives a pool of candidate models at any given time, each of which can be developed under different hypotheses (e.g., different slices of data). While real-world data distribution keeps changing rapidly (e.g., every day), how can we pick the best model, i.e. the one that fits our latest data distribution?